凡此过往,皆为序章。(前方未知的未来,由你我的双手铺就。)
Intro
前段时间承蒙导师信任,被安排前去参加曾经梦寐以求的数据科学界的Kaggle竞赛,根据队中哥哥姐姐们的兴趣与他们选定了Titanic与MNIST两道题目,虽然做的工作很少,但也算是为这两道(大水)题处心积虑煞费苦心。
虽由于网络原因尚未提交submission,但这两个project的accuracy已经达到预期目标,可以告一段落。
而在后面,还有我们最终要做的基于GAN生成Monet作品一项,目前征程尚未结束,我还需要继续努力。(但是现在来考虑,至于还要不要做那道题目,可能是未知数,因为我们可能会换作进行别的project)
(最近要复习数学和代数的期中考试,因此一直没有整理这一块的内容QAQ)
Neural Style Transfer
基于VGG19与L-BFGS-B优化算法的NST(神经样式迁移)。
Abstract
这个project最早是2018年年底在Keras之父所著的《Deep Learning with Python》上关于生成式深度学习一部分看到的,NST这个算法经常被与DeepDream算法一并提起,后者DeepDream是向给定的现实图像注入细节以生成魔幻(非)现实主义的“梦境”图像。
但我们今天讨论的重点在于前者亦即神经样式迁移,这是由Leon A. Gatys, Alexander S. Ecker, Matthias Bethge三人于文献《A Neural Algorithm of Artistic Style》提出的,与DeepDream拥有诸多相同之处。
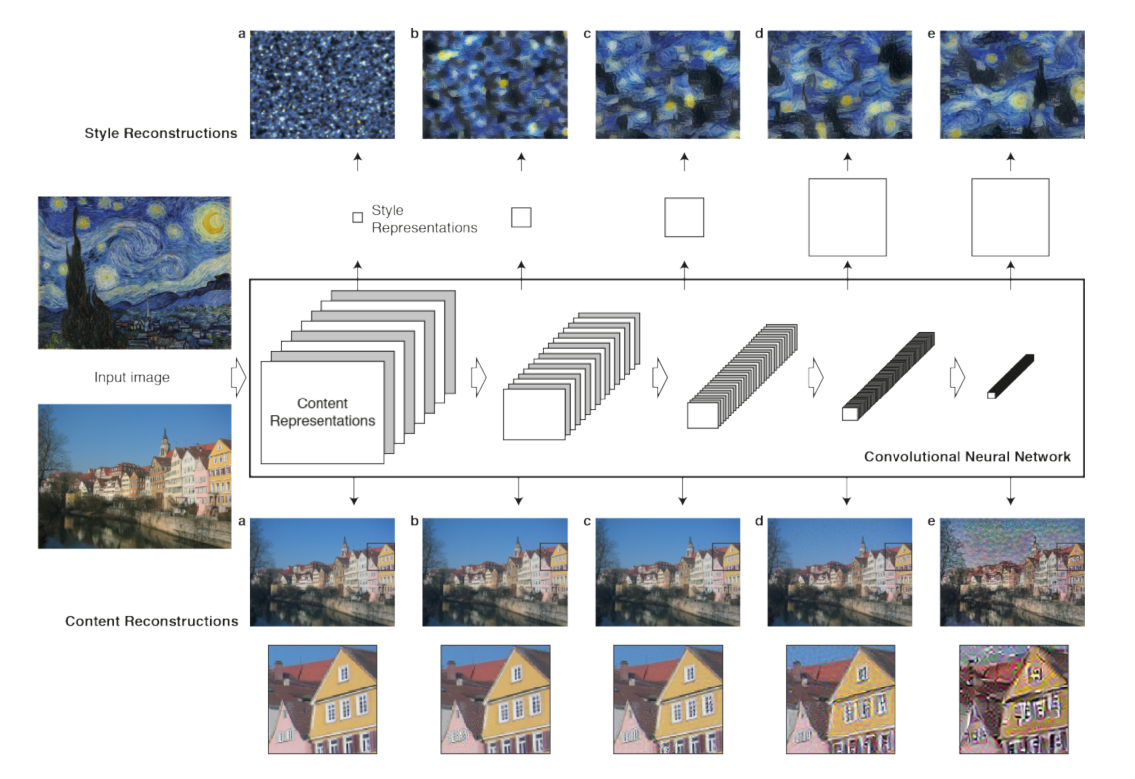
其目标在于改变现实图像的细节,以使生成图像具备参考图像的画风,例如使一张现实中的青岛市中山路街道夜景变得像梵高画出来的一样,在像这样的过程之中便可以参考梵高的的《Starry Night》以进行变换。
下面这幅图生动传神地刻画了现实图像被注入目标风格的过程(,虽说操作的对象并不是中山路街道夜景就是啦)
Keywords:
- Neural Style Transfer (NST)
- VGG19
- Gram Matrix
- L-BFGS-B
…
Loss Functions
作为文献作者的Gatys认为在convnet之中图像的内容与样式被在后面的层中分立表示,例如Gatys老哥用的VGG19中,最后一个block倒数第三个卷积层(即block5_conv2)被用于表示进入convnet被处理的现实图像的内容,而每一个block的第一个卷积层(block1_conv1,block2_conv1…一直到block5_conv1都是)皆被用于表示进入convnet被处理的现实图像的样式。
用convnet中不同的层的隐层输出表示内容和样式之后,可以定义相应的内容损失content_loss和样式损失style_loss,内容损失很好理解其实就是生成图像与现实图像的特征图之间的差量再平方,这就比较类似于我们所熟悉的mse,如若是绝对值的话(我觉得可能)也可以,就比较类似于mae。
与内容损失不同,样式损失通过一个叫做Gram Matrix的东西来进行刻画:
或是千言万语不及一幅图?
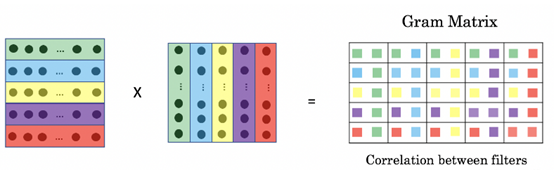
所以我们可以从公式或者图看出,这个Gram Matrix实质上就是把矩阵视为一个矢量组,让矢量组之间互相点积得到的结果,所以能够反映出矩阵内部矢量与矢量之间的自相关性。这样的相关性从convnet较高层一直保留到较低层,从而保留的是样式。特征相互关系捕捉到的是纹理(texture),生成图像和参考图像纵使在不同的空间尺度上亦应当具有相同的纹理。
除内容与样式之外,我们还要考虑生成图像的连贯性或者说连续性,以避免生成的结果过度像素化以至于令人感到非常违和,因此Gatys老哥还定义了总变差损失total_variation_loss,简单地说就是:
(这个project在梯度下降过程之前用到的只是一些简单的对张量的数值代数处理,因此我们
2
import keras, keras.backend as T)
1 | def total_variation_loss(x): |
对生成图像取了从左上角到倒数第二列倒数第二行的窗口,分别与窗口向右、向下平移一格的窗口作差。这个新定义的损失与我们见过的各种损失同样不可能为零,毕竟除了纯色图之外不可能所有的点与其相邻的点颜色一模一样。明确了三类需要的损失之后,最终需要优化的损失便是三者之和:
Optimization
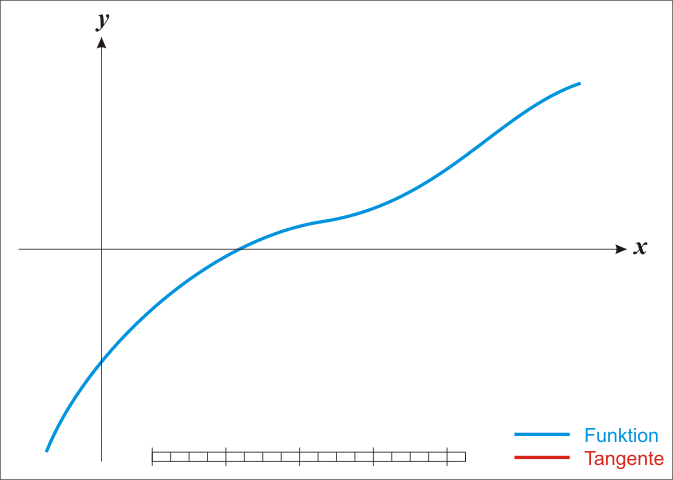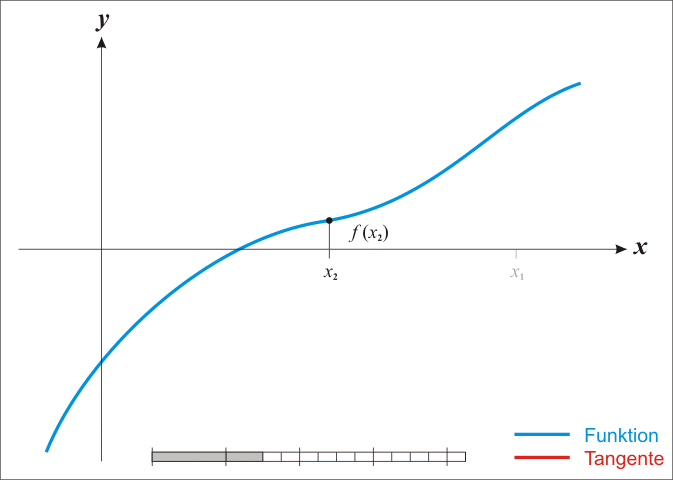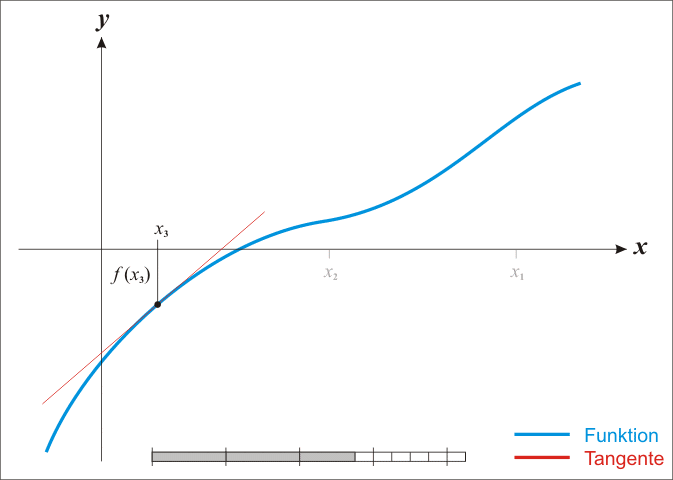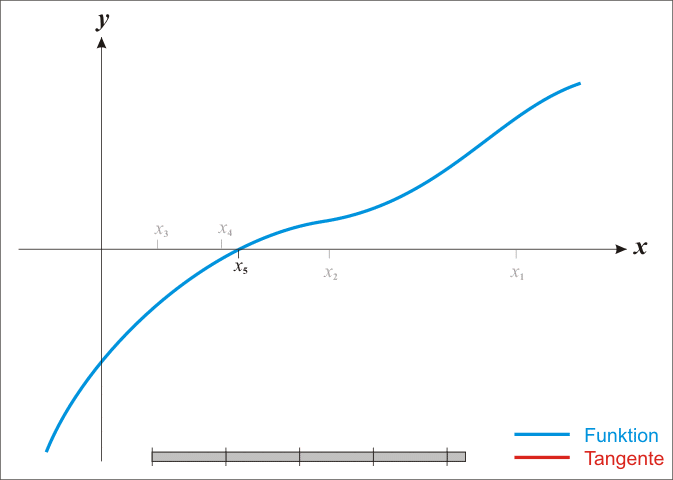
采用L-BFGS-B算法进行优化,BFGS算法是由Broyden, Fletcher, Goldfarb, Shanno四名科学家提出的优化牛顿迭代法的产物,其改进版L-BFGS算法中的L指代limited_memory即对内存的限制,而再次改进的L-BFGS-B算法中的B指代bound即进一步使L-BFGS支持了极小化过程中对变量施加约束。总的来说这一套发展路程差不多就是Newton -> BFGS -> L-BFGS -> L-BFGS-B,而牛顿迭代法可以通过下方的动图加以理解:
Code
最后我们放一下代码:
1 | #!/usr/bin/env Python |
Summary


在2018年年底看到之后我于2019年1月28日进行第一次实验,但是第一次实验的结果非常不尽人意,现在回想原因大致是设反了参数,于是得到了一个横版图像被挤压为竖版的效果:
这个project持续了将近两年,期间因高考而鸽置,然而在将近两年之后的某一个平凡无奇的清晨,终于得到了结果:
Latent Space Generating
基于VAE(Variational AutoEncoder, 变分自编码机)的手写数字图片(MNIST)潜在连续空间生成。
Abstract
这个project最早是2019年年初在Keras之父所著的《Deep Learning with Python》上关于生成式深度学习一部分看到的。VAE的原型,AutoEncoder即自编码机,经常被与GAN(Generative Adversarial Networks, 生成对抗网络)一并提起,因为两者皆是兼具类似于生成与类似于预测两套模型的组合。
但是AutoEncoder为Encoder(编码机)和Decoder(解码机)的组合,GAN为Generator(生成机)和Discriminator(判别机)的组合,可以认为后者GAN偏向于一个自带数据增强的预测模型。而且在结构上AutoEncoder把两个子结构合二为一一并使用,以最后输出的图像尽可能还原输入的图像为目标,隐层的节点数先逐渐递减再逐渐增加,因此AutoEncoder经常被用于降维任务;而GAN则是轮流训练Generator与Discriminator,直到二者达到动态平衡,因此GAN经常被用于数据增强。另外,二者各有缺点,AutoEncoder的容易生成失真,GAN的容易保留噪声。
除了VAE之外AutoEncoder还有Denoising AutoEncoder和Sparse AutoEncoder两个亚种,感兴趣的话可以上网搜一下,但是内容预算有限,在此暂不赘述。
Keywords:
- AutoEncoder
- VAE
…
AutoEncoder
我们先从VAE的原型,即AutoEncoder讲起。

这就是AutoEncoder(大误
没错,AutoEncoder说穿了无非就是先压缩再解压回去,或者说先降维再升回去,因此朴素AutoEncoder可以用Keras简单刻画如下:
1 | import keras, keras.backend as T |
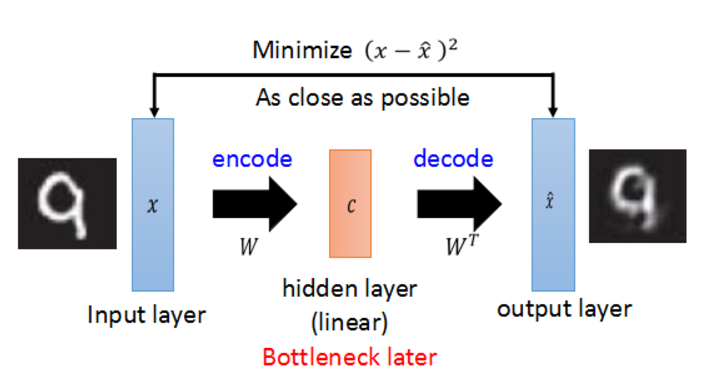
如代码中所示一样,以MNIST为例,输入一张28x28的灰度图像在中间的Bottleneck会被压缩为一个二维矢量,这直接就可以在一个二维平面上把某张图片所在潜在连续空间中的位置表示出来。在学习较大输入数据的时候可以先把大的输入数据压缩为一个较短的低维矢量进行表示,然后学习被压低的这一块“精髓”。如同下面图片的这张图片:
VAE
既然AutoEncoder这么流弊,那么为什么还要出这么个亚种呢?
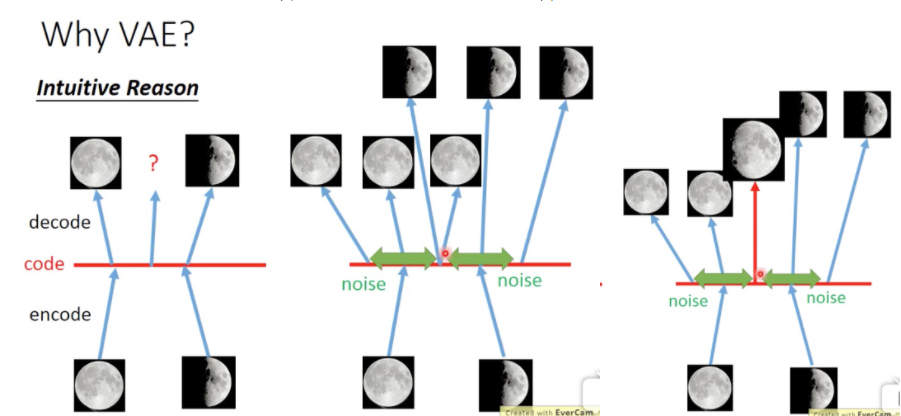
如上图所示,我们拿满月和弦月的图片训练AutoEncoder,对于AutoEncoder而言,在满月编码的点附近的一块邻域内解码出的图片都是与满月类似,在弦月附近的一块领域内解码出的也都与弦月类似。但是如若我们取两个领域正中间的点进行解码,那么可能什么都解不出来。于是我们对解码过程的起手注入随机噪声,这一块噪声的构成方式是由模型学习得到的,且服从于常态分布,使得在两点之间可以解出介于满月与弦月之间的点,从而构造手写数字图片(MNIST)的潜在连续空间。
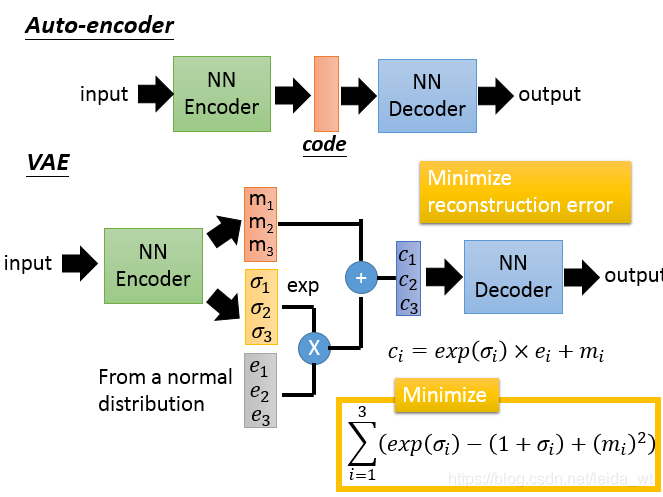
这幅图对比了AutoEncoder与VAE。
Code
最后我们还是要放一下代码:
1 | #!/usr/bin/env Python |
Summary
从2019年4月开始尝试到现在,这个project大概持续了一年半,重构程式的时候非常顺利,所以也没什么令人惊喜之感。
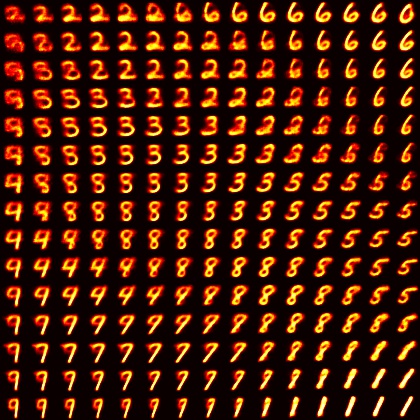
Summary
この空をあの星を 奇跡さえ超えて君の元へ
超越這片天空那顆星星 超越奇蹟穿梭到你身邊
翔べるよ何処までも 今ならきっと大丈夫
不論到何處都展翅翱翔 若是現在肯定沒有問題
この歌はこの声は いつも君の隣にある
這首歌曲和這份歌聲 一直都存在你身邊
届けたい 終わりのない空を翔ける星のメロディ
想要傳達 在這無盡的天空飛翔的星之旋律
★﹣ ﹦ ≡☆﹣ ﹦ ≡★﹣ ﹦ ≡☆﹣ ﹦ ≡★﹣ ﹦ ≡☆﹣ ﹦ ≡★﹣ ﹦ ≡☆﹣ ﹦ ≡
巡り会うこの場所で 君と二人の夜空を見る
在相逢的這個地點 與你一起仰望兩人的夜空
駆け出して それだけできっと夢は叶うから
只要開始向前奔跑 夢想就一定能夠實現
この歌をこの声を ずっと忘れないでいてね
這首歌曲和這份歌聲 請永遠不要忘記喔
届けたい 遥か遠いミライ
想要傳達 直到遙遠的未來
★﹣ ﹦ ≡☆﹣ ﹦ ≡★﹣ ﹦ ≡☆﹣ ﹦ ≡★﹣ ﹦ ≡☆﹣ ﹦ ≡★﹣ ﹦ ≡☆﹣ ﹦ ≡
翔ける
飛翔吧
★﹣ ﹦ ≡☆﹣ ﹦ ≡★﹣ ﹦ ≡☆﹣ ﹦ ≡★﹣ ﹦ ≡☆﹣ ﹦ ≡★﹣ ﹦ ≡☆﹣ ﹦ ≡
翔ける
飛翔吧
★﹣ ﹦ ≡☆﹣ ﹦ ≡★﹣ ﹦ ≡☆﹣ ﹦ ≡★﹣ ﹦ ≡☆﹣ ﹦ ≡★﹣ ﹦ ≡☆﹣ ﹦ ≡
全速力のメロディ
全速的旋律
References
NST (Neural Style Transform)
- [1]: https://arxiv.org/abs/1508.06576/
- [2]: https://www.jianshu.com/p/9f03b61fdeac
- [3]: https://blog.csdn.net/Cowry5/article/details/81037767
- [4]: https://blog.csdn.net/level_code/article/details/94631322
Gram Matrix
L-BFGS-B
- [7]: http://sepwww.stanford.edu/data/media/public/docs/sep117/antoine1/paper_html/node6.html
- [8]: https://blog.csdn.net/weixin_39445556/article/details/84502260/
- [9]: http://users.iems.northwestern.edu/~nocedal/software.html
- [10]: http://sobereva.com/538/
AE (AutoEncoder)
- [11]: https://www.bilibili.com/video/av15998800/
- [12]: https://blog.csdn.net/leida_wt/article/details/85052299/
- [13]: https://www.alwa.info/2016/Autoencoder-详解.html
- [14]: https://www.cnblogs.com/yangmang/p/7530463.html